DeepSeek prezentē jauno V3.2-exp modeli ar retināto uzmanību, kas uz pusi samazina ilgtermiņa interfeisa izmaksas.
Ķīnas mākslīgā intelekta (MI) uzņēmuma DeepSeek pētnieki pirmdien izlaida jaunu eksperimentālu modeli ar nosaukumu V3.2-exp, kā galvenais mērķis ir būtiski samazināt izmaksas ilgstošas konteksta apstrādes laikā.
Paziņojums publicēts platformā Hugging Face, vienlaikus ar akadēmisko rakstu, kas ievietots GitHub.
Galvenais jaunā modeļa elements ir DeepSeek Sparse Attention jeb retinātā uzmanība. Tā ir sarežģīta sistēma, kuras darbību uzņēmums attēlojis ar detalizētu shēmu.
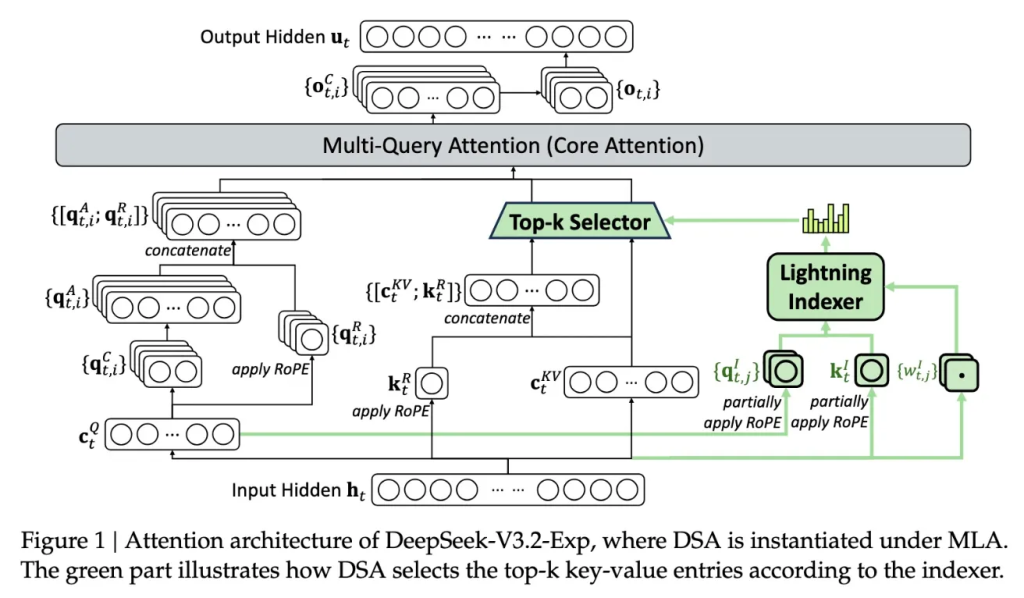
Vienkāršoti sakot, sistēma izmanto moduli ar nosaukumu “lightning indexer”, lai atlasītu būtiskākos fragmentus no plašā konteksta loga.
Pēc tam cita apakšsistēma, proti, “fine-grained token selection system”, izvēlas konkrētus tokenus no šiem fragmentiem, lai tos ielādētu ierobežotajā uzmanības logā. Šo procesu apvienojums ļauj apstrādāt lielus teksta apjomus, ievērojami mazāk noslogojot serverus.
Pēc sākotnējiem DeepSeek testiem, vienkārša API pieprasījuma cena šādos apstākļos varētu sarukt pat uz pusi.
Lai gan nepieciešami papildu eksperimenti, fakts, ka modelis ir atvērts un pieejams bez maksas Hugging Face, nozīmē, ka neatkarīgi pārbaudītāji drīzumā varēs novērtēt pētījumā izteiktos apgalvojumus.
DeepSeek jaunākais darbs ir daļa no plašākām MI industrijas inovācijām, kas vērstas uz interfeisa izmaksu samazināšanu. Ar to jāsaprot serveru izmaksas, kas rodas, darbinot jau apmācītu modeli, atšķirībā no paša apmācības procesa.
Pētnieku mērķis bijis panākt, lai transformatoru arhitektūra darbotos efektīvāk, un rezultāti norāda, ka šajā jomā ir ievērojamas uzlabojumu iespējas.
DeepSeek piedāvā citādāku pieeju
Šī gada sākumā DeepSeek nonāca uzmanības centrā ar savu R1 modeli. Tas tika apmācīts galvenokārt izmantojot pastiprināto mācīšanos, turklāt tas tika paveikts ar ievērojami zemākām izmaksām nekā, piemēram, ASV konkurentu gadījumā.
Lai arī tas nesagādāja gaidīto revolūciju MI apmācībā, uzņēmums parādīja, ka iespējams darboties efektīvāk. Turklāt Ķīnā bāzētajam uzņēmumam izdevās izcelties ar neparastu pieeju laikā, kad daudzi MI uztver kā sacensību lielvaru starpā.
Jaunā retinātās uzmanības metode, visticamāk, neizraisīs tādu pašu ažiotāžu kā R1, taču tā var kļūt par vērtīgu mācību Amerikas MI uzņēmumiem, kas meklē risinājumus, kā maksimāli samazināt interfeisa izmaksas.
Avots: TechCrunch